CXL Memory Pooling: DRAM, Flash and the AI Stack
6/21/2026
CXL memory pooling is quietly rewiring the AI data center, letting servers share a common reservoir of DRAM and flash instead of hoarding their own. Here is how CXL + DRAM and CXL + Flash actually work, why the AI memory wall makes them urgent, and how investors can play the theme through names like Astera Labs (ALAB) and Sandisk (SNDK).
What Is CXL Memory Pooling?
Compute Express Link (CXL) is an open, industry-standard interconnect that runs on top of the PCIe physical layer and lets a CPU or accelerator treat external devices as if they were local memory. CXL memory pooling takes that one step further: instead of bolting memory permanently inside each server, you connect several CXL memory devices to a CXL switch to form a single large-capacity pool, then let many servers "draw" memory from that pool on demand.
It is the difference between every apartment owning its own rarely-used pickup truck and a building sharing a small fleet that any tenant can book when they need it. The total amount of expensive hardware drops, and utilization climbs.
The memory wall problem
For two decades, compute performance has grown far faster than memory bandwidth and capacity. This widening gap is the memory wall, and AI has slammed straight into it. Large language models routinely exceed 80 to 120GB per GPU just for their key-value (KV) cache, the running memory of an inference session, and that demand scales linearly with context length and batch size. The chips are starving for memory, not compute.
We covered the supply side of this crunch in our deep dive on the 2026 AI memory bottleneck. CXL pooling is the architectural answer to the same problem: if you cannot put enough fast memory next to each GPU, give every server access to a shared ocean of it instead.
From a PCIe bus to a memory fabric
The clever part is that CXL reuses the PCIe electrical and physical layers that already exist in every server, then layers memory-semantic protocols on top. That means no exotic new cabling and a clean upgrade path tied to each PCIe generation. CXL 3.0, for example, rides PCIe 6.0 signaling to roughly 64 GB/s per direction on an x16 link and adds multi-level switching, turning a point-to-point bus into a true rack-scale memory fabric.
How CXL Works: Protocols, Versions, and Latency
CXL is not one protocol but three, multiplexed over the same link. Understanding them clarifies exactly what "pooling" can and cannot do.
- CXL.io - handles device discovery, configuration, and register access. It is essentially PCIe and provides the plumbing.
- CXL.cache - lets an accelerator coherently cache host memory, so a GPU or DPU can keep a consistent view of CPU data.
- CXL.mem - the heart of pooling. It gives the host a low-latency, load/store path to memory that physically sits on the CXL device.
CXL 1.1, 2.0, and 3.0
Each version unlocked a bigger sharing model. CXL 1.1 enabled simple memory expansion for a single host. CXL 2.0 introduced memory pooling, letting multiple hosts share common memory devices through a switch, each with its own private allocation. CXL 3.0 added true shared memory, where multiple hosts can read and write the same memory segment with a coherent view, plus fabric-style multi-level switching that is expected to spread after 2026.
| CXL version | PCIe base | Headline capability | Sharing model |
|---|---|---|---|
| CXL 1.1 | PCIe 5.0 | Memory expansion | Single host, dedicated |
| CXL 2.0 | PCIe 5.0 | Switching and pooling | Many hosts, partitioned |
| CXL 3.0 / 3.1 | PCIe 6.0 | Fabrics and shared memory | Many hosts, coherent sharing |
The latency tax
Pooling is not free. Local DRAM answers in roughly 50 to 100 nanoseconds. A CXL-attached memory access typically lands around 150 to 300 nanoseconds, because each request travels through the host cache, the CXL protocol stack, the off-chip wires, and the remote DRAM, and a CXL switch adds more. In round numbers, CXL memory behaves like a tier that is about 2x to 3x slower than the memory soldered next to the CPU.
That is exactly why CXL slots between local DRAM and storage in the hierarchy rather than replacing main memory. The winning strategy is tiering: keep hot data in local DRAM and migrate cold or infrequently touched pages out to the CXL pool, which in practice can free roughly 40% of host DRAM for the work that actually needs the speed.
CXL + DRAM: Pooling the Most Expensive Resource
DRAM is the first and most mature CXL use case, and for good reason. Server DRAM is one of the largest line items in a data center bill of materials, and most of it sits idle most of the time. CXL attacks that waste from three angles.
Memory expansion
A CPU has a fixed number of DIMM slots and memory channels. Once they are full, the only way to add capacity has been to buy another whole server. A CXL memory module (sometimes branded CMM-D) plugs into a CXL/PCIe slot and adds capacity and bandwidth beyond what the motherboard's channels allow. Samsung, SK Hynix, and Micron Technology (MU) all ship CXL-attached DRAM modules, with capacities up to 256GB per module already commercially available.
Memory pooling and disaggregation
Expansion helps one server; pooling helps the whole rack. By placing DRAM behind a CXL switch, operators disaggregate memory from compute and reallocate it dynamically based on real demand rather than provisioning every server for its worst case. The payoff is fewer total DRAM modules per rack at the same effective service level, which is a direct cost takeout in an era of surging DRAM prices. Marvell Technology (MRVL) has pushed this vision with next-generation CXL switches explicitly aimed at memory pooling to break the AI memory wall.

Real deployments are already live
This is no longer a whiteboard concept. Astera Labs (ALAB) has its Leo CXL Smart Memory Controllers ramping on Microsoft (MSFT) Azure M-series virtual machines, with the controller used to overcome the memory wall on memory-heavy instances. Commercial CXL pools reached the 100 TiB scale in 2025, and hyperscalers including Amazon (AMZN), Google parent Alphabet (GOOGL), and Meta (META) have all signaled multi-year infrastructure plans that explicitly include CXL-capable memory subsystems.
CXL + Flash: Pushing NAND Up the Memory Hierarchy
If CXL + DRAM is about sharing expensive memory, CXL + Flash is about a more radical idea: dragging cheap NAND flash up out of the storage basement and into the memory tier. There are two related but distinct flavors investors should not confuse.
Flash as a CXL "far memory" tier
The first flavor attaches NAND-based SSDs behind the CXL.mem protocol so the host can address them with load/store semantics, creating a vast and inexpensive tier below DRAM. It is far slower than DRAM, so it only suits cold data and capacity-bound workloads, but for the right access patterns it is dramatically cheaper per gigabyte. NVIDIA (NVDA) already leans on this idea: its Dynamo inference framework cascades KV cache from GPU HBM down to CPU DRAM, then to local SSD, then to networked storage, and its Inference Context Memory Storage Platform standardizes offloading context to NVMe flash.
High Bandwidth Flash (HBF): NAND that mimics HBM
The second flavor is the one generating headlines. High Bandwidth Flash (HBF), co-developed by Sandisk (SNDK) and SK Hynix, is a brand-new memory tier that sits between HBM and the SSD. It uses 3D NAND as its core medium but borrows the advanced stacking and packaging of HBM, so it can match an HBM stack's physical footprint, power profile, and height while delivering far more capacity.
The specs are striking. The first-generation HBF targets read bandwidth of 1.6 TB/s, packs 256Gb per die, and reaches 512GB per 16-die stack, closely matching the dimensions of HBM4. Sandisk claims HBF can deliver "up to 8x to 16x" the capacity of HBM at similar bandwidth and similar system cost. First samples are targeted for the second half of calendar 2026, with the first AI-inference devices using HBF expected in early 2027, and the two companies have opened an Open Compute Project workstream to standardize it.
Strictly speaking, HBF is an on-package HBM rival, not a CXL device. But it belongs in any CXL + Flash discussion because it is the same strategic bet: NAND is no longer just storage, it is becoming a legitimate rung on the memory ladder. For background on how NAND and DRAM differ at the cell level, see our explainer on the DRAM vs NAND memory bottleneck.
Why flash for KV cache?
KV cache is the perfect target for cheaper tiers because much of it is read-heavy and reused across requests, especially for long-context and multi-turn inference. Research on offloading KV cache to CXL memory has shown GPU memory usage cut by up to 87% while still meeting latency targets. Move the coldest slices to flash and the hottest to DRAM or HBM, and you serve longer contexts and bigger batches on the same GPUs.
Why Does AI Make CXL Pooling Matter Now?
CXL has existed on paper since 2019. What changed is the economics of inference. Three forces turned a nice-to-have into a budget priority.
- KV cache is exploding. Because cache size grows with both context length and the number of concurrent users, the memory bill for a popular model can dwarf the cost of the compute running it.
- HBM is scarce and expensive. Micron projects the HBM total addressable market hitting roughly $100 billion by 2028, up from about $35 billion in 2025. When the fastest memory is sold out and priced like jewelry, any tier that offloads pressure from it has obvious ROI.
- Stranded memory is real money. Studies of large fleets repeatedly find a large share of provisioned DRAM sitting unused because each server is sized for peak. Pooling recovers that capital.
Put differently, CXL pooling is a margin lever. For a deeper look at how the AI hardware narrative is being repriced in 2026, our piece on whether the AI trade is cracking is a useful companion. You can also gauge today's macro and sentiment backdrop in the AI-generated market intelligence report.
The Memory Tiering Stack: HBM, DRAM, CXL, Flash
The cleanest way to think about all of this is as a ladder, where each rung trades speed for capacity and cost. CXL adds new rungs in the middle that did not exist a few years ago.
| Tier | Approx. latency | Relative cost / GB | Role in AI inference |
|---|---|---|---|
| HBM (on-package) | ~10-20 ns | Highest | Active weights and hot KV cache |
| Local DRAM (DIMM) | ~50-100 ns | High | Working set, warm data |
| CXL-attached DRAM (pool) | ~150-300 ns | Medium-high | Overflow capacity, warm KV cache |
| HBF (NAND on-package) | Sub-microsecond | Medium | Large read-heavy KV cache |
| CXL / NVMe flash (far memory) | Microseconds | Low | Cold cache, capacity tier |
The investable insight is that almost every rung now has a public-market supplier. HBM and DRAM run through the big three memory makers; the CXL controllers and switches that knit the tiers together run through specialists like Astera Labs and Marvell; and the flash rungs run through Sandisk and its peers. You can compare the fundamentals of any of these names side by side using the Finance Halo stock screener.
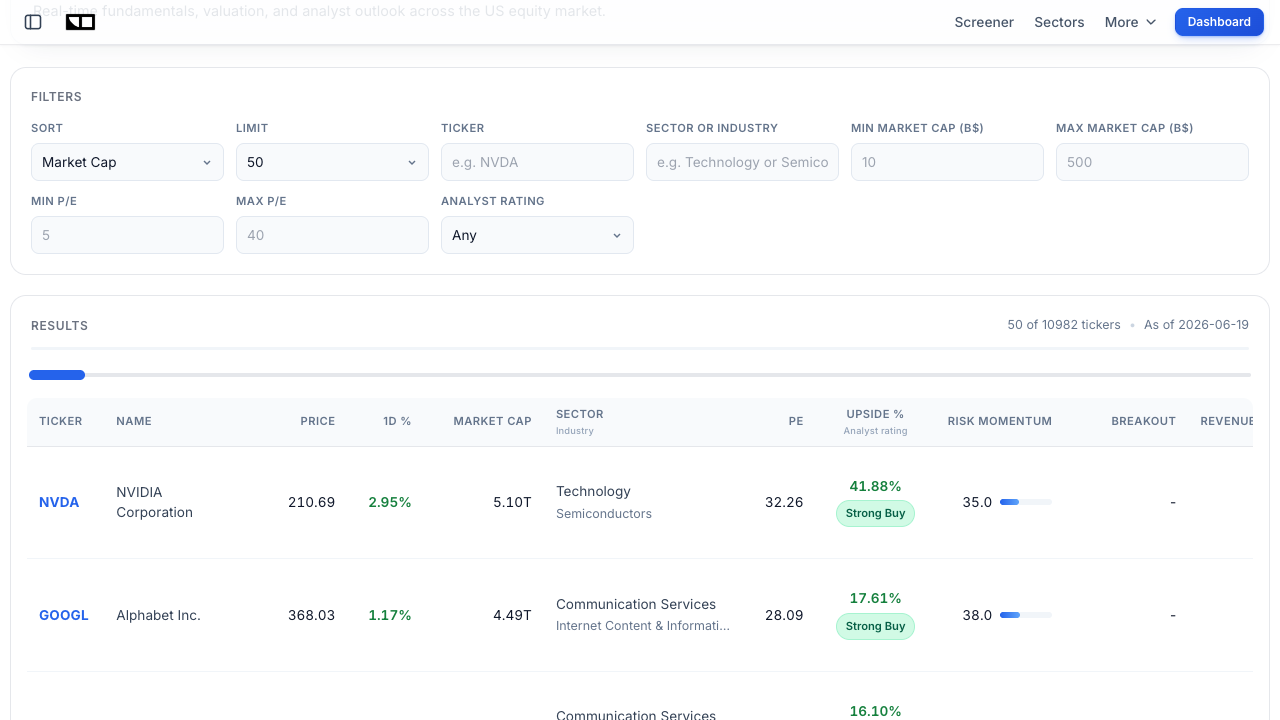
Astera Labs (ALAB): The Connectivity Pure-Play
Astera Labs (ALAB) is arguably the purest listed way to play CXL connectivity. Its Intelligent Connectivity Platform spans four product families: Aries PCIe retimers, Taurus Ethernet smart cable modules, Scorpio PCIe fabric switches, and, most relevant here, the Leo CXL Smart Memory Controllers that make memory expansion and pooling possible.
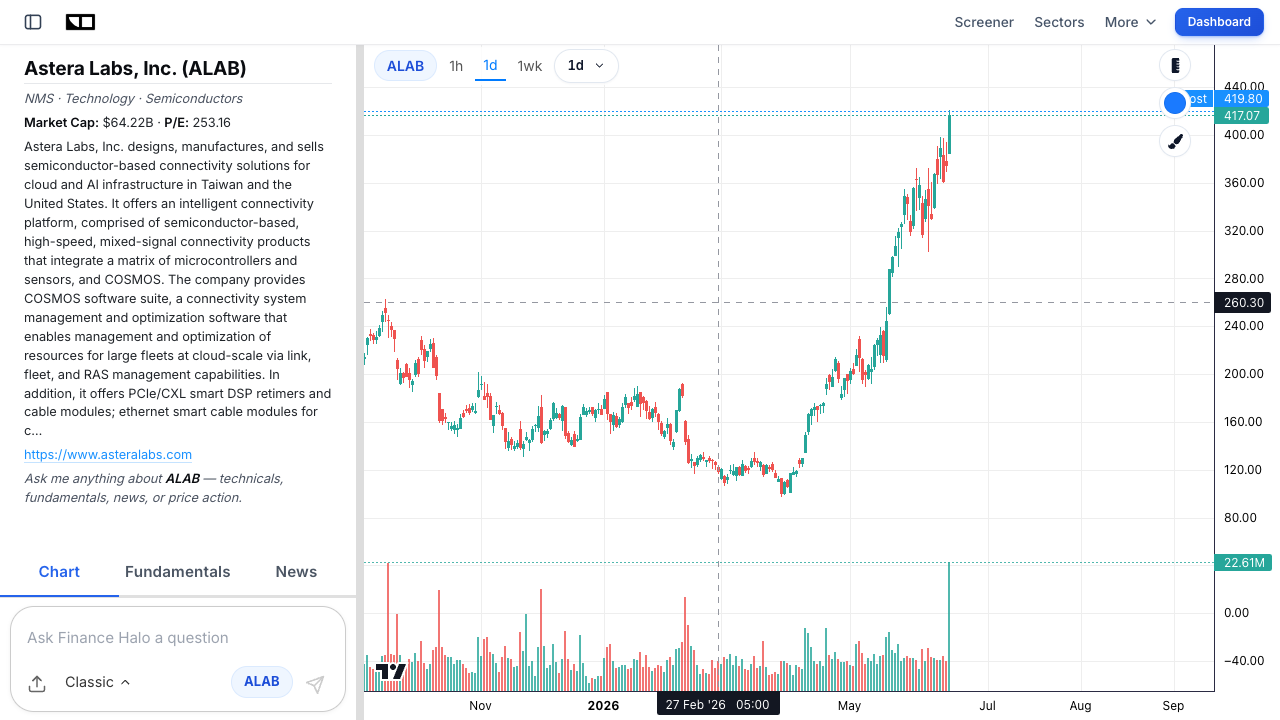
The numbers
The business is growing at a blistering pace. In Q1 2026, Astera Labs reported revenue of $308.4 million, up 93% year over year, and guided Q2 to $355 million to $365 million. It has beaten estimates for five straight quarters, grew the trailing twelve-month top line more than 115%, and carries a forward two-year revenue CAGR estimate around 60%. On the CXL side specifically, management flagged a custom Leo design win aimed at KV cache offload, with shipments expected in 2027, plus the live Azure M-series ramp.
The valuation
The catch is the price tag. Around $417, ALAB has traded at a next-twelve-month EV/EBITDA north of 100x and a forward price-to-sales near 39x, versus a semiconductor peer mean closer to the mid-30s on EV/EBITDA. In other words, the market already assumes years of flawless execution. That makes the stock a high-beta expression of the CXL thesis: enormous upside if pooling adoption compounds, but little margin for a stumble. If you want to understand why a rich forward multiple can still be defensible (or not), our guide to forward vs trailing P/E is worth a read.
Sandisk (SNDK): The Flash Side of the Trade
Sandisk (SNDK) is the flash counterpart. Spun out of Western Digital (WDC) in February 2025 at roughly $38.50 a share, Sandisk was treated as a sleepy NAND business for about five minutes. Then a genuine shortage of AI-grade flash collided with a thin post-spinoff share float, and the stock went vertical, climbing thousands of percent and pushing above $2,000 a share by mid-2026.
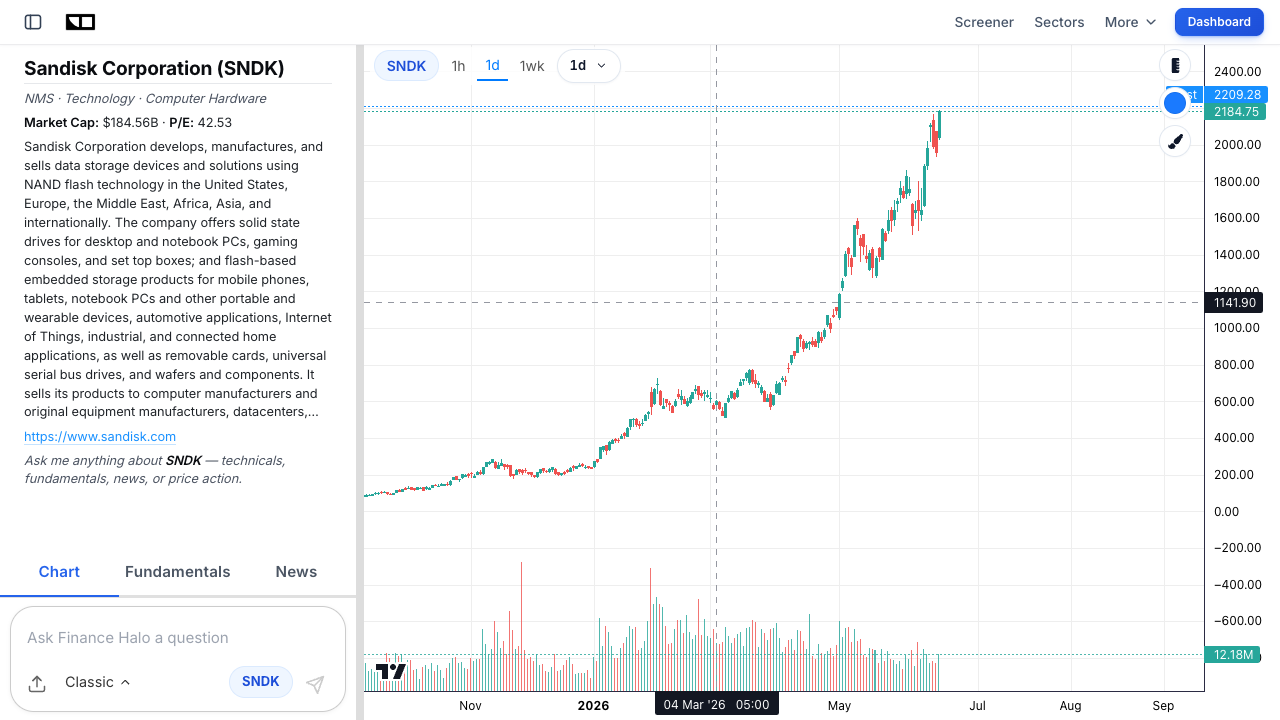
Why it matters for CXL + Flash
Beyond selling the enterprise SSDs that AI data centers rely on, Sandisk is the lead architect of HBF. If High Bandwidth Flash standardizes and ships into inference servers in 2027 as planned, Sandisk moves from commodity storage vendor to a supplier of a differentiated AI memory tier, a far better place to sit in the value chain. That optionality is a big part of the bull case.
The valuation reality check
The same caution applies, only louder. After a parabolic run, SNDK has carried a market capitalization near $185 billion and a P/E in the 40s to 70s depending on the day and the earnings base, and the Wall Street consensus average price target has at times sat roughly 20% below the share price. A stock can be a great company and a stretched stock at the same time. The cleanest framing here borrows from our guide to value vs momentum thinking: momentum names like this can run far past fair value in both directions.
Real-World Example: Sizing a CXL Memory Pool
Make it concrete. Imagine a rack of 16 inference servers, each historically provisioned with 1.5TB of DRAM to cover peak KV cache demand, for 24TB of DRAM total. In practice, monitoring shows average utilization of just 55%, because the peaks rarely line up across servers.
With CXL pooling, the operator gives each server a smaller 768GB local allocation (12TB total) and adds a shared 6TB CXL DRAM pool that any server can borrow from during its spikes.
- Before: 24TB DRAM, ~55% utilized, large stranded capacity.
- After: 12TB local + 6TB pooled = 18TB provisioned, a 25% reduction in DRAM purchased.
- Trade-off: borrowed pages answer in ~200 ns instead of ~80 ns, acceptable for warm KV cache but not for the hottest weights.
The 6TB pool needs CXL memory controllers (Astera's Leo is one option) and a CXL switch (Marvell and others). That single rack-level decision is the entire investment thesis in miniature: a measurable DRAM cost takeout that creates demand for controllers, switches, and eventually flash tiers. A useful sanity check before extrapolating one rack to a $15 billion market is our framework on how to analyze a stock before buying.
Is CXL a Buy? The Bull and Bear Case
CXL is genuinely contested, and a good investor holds both views at once.
The bull case
- Hard ROI. Pooling cuts the single biggest non-GPU cost in the rack. That sells itself.
- Standards momentum. CXL is backed by essentially the entire industry, and CXL 3.x fabrics open shared-memory designs that did not exist before.
- Market scale. Some forecasts put the CXL market near $15 billion to $16 billion by 2028 with server attach rates around 30%, with the bulk of that value in the DRAM riding behind CXL.
The bear case
- The latency tax. A 2x to 3x latency penalty means CXL only helps specific access patterns, and some skeptics argue that in the most demanding AI workloads, on-package HBM and tight NVLink-style fabrics simply leave CXL on the sidelines.
- Forecast spread. Market estimates vary wildly, from a couple of billion to over fifteen billion dollars by the late 2020s. That dispersion is a tell that adoption timing is genuinely uncertain.
- Valuation. The pure-plays already price in success. The technology can win while the stocks still fall if growth merely meets, rather than crushes, expectations.
For most investors, the sober conclusion is that CXL is a real, multi-year architectural shift, but the listed pure-plays are momentum vehicles that demand position sizing and a plan. Screen the broader memory and connectivity complex, including lower-multiple incumbents like Micron and Marvell, on the Finance Halo screener before chasing the hottest chart.
Common Mistakes to Avoid
- Confusing HBF with CXL. High Bandwidth Flash is an on-package HBM alternative, not a CXL device. They serve the same memory-wall theme but are different architectures with different competitors.
- Treating CXL as a DRAM replacement. It is a tier between DRAM and storage. Anyone modeling CXL eating all server DRAM misunderstands the latency math.
- Anchoring on a single market forecast. Estimates range from low single-digit billions to $16 billion by 2028. Use a range, not a point.
- Buying the story and ignoring the multiple. ALAB and SNDK can be correct on technology and still draw down 30%+ from stretched valuations. Size accordingly.
- Forgetting the incumbents. The biggest dollar beneficiary of "DRAM behind CXL" may be the memory makers themselves, not just the controller specialists.
- Ignoring lock-up and float dynamics. Part of SNDK's violent move traces to a thin post-spinoff float, with Western Digital only unwinding its final stake in mid-2026. Technical, not just fundamental, forces are at work.
Frequently Asked Questions
What is CXL memory pooling in simple terms?
It is a way for many servers to share one common pool of memory through a high-speed CXL switch, instead of each server owning a fixed block of DRAM it rarely fully uses. Servers borrow capacity from the pool when they need it and release it when they do not, which raises utilization and cuts the total amount of memory a data center has to buy.
Is CXL faster than DRAM?
No. Local DRAM responds in about 50 to 100 nanoseconds, while CXL-attached memory typically takes 150 to 300 nanoseconds. CXL trades some speed for far more capacity and flexibility, which is why it is used as a tier below local DRAM rather than as a replacement for it.
What is the difference between CXL + DRAM and CXL + Flash?
CXL + DRAM pools fast, volatile memory across servers for overflow capacity and warm data. CXL + Flash attaches much cheaper, slower NAND as a far-memory tier for cold or read-heavy data. DRAM pooling is mature and shipping today; flash-based tiers, including Sandisk's HBF, are earlier and aimed mainly at large AI inference caches.
How does CXL help with AI and KV cache?
Large language model inference stores a key-value cache that can consume 80 to 120GB per GPU and grows with context length and batch size. Offloading that cache to CXL memory has been shown to cut GPU memory use by up to 87% while still meeting latency targets, letting the same GPUs serve longer contexts and more users.
What stocks are exposed to CXL memory pooling?
On the controller and switch side, Astera Labs (ALAB) and Marvell (MRVL) are the most direct names. On the memory side, Micron (MU), plus Samsung and SK Hynix, supply CXL-attached DRAM, while Sandisk (SNDK) leads on the flash side with High Bandwidth Flash. You can compare them on the Finance Halo screener.
Is Astera Labs (ALAB) stock a good buy?
Astera Labs is a fast-growing, high-quality way to play CXL connectivity, with revenue up 93% year over year in Q1 2026. The risk is valuation: it has traded at well over 100x forward EV/EBITDA, so the stock prices in years of strong execution and can fall sharply if growth merely meets expectations. It suits investors comfortable with high volatility and small position sizes.
What is High Bandwidth Flash (HBF)?
HBF is a new memory tier from Sandisk and SK Hynix that stacks 3D NAND using HBM-style packaging. It targets 1.6 TB/s of read bandwidth and up to 8x to 16x the capacity of HBM at similar cost, aimed at AI inference. First samples are expected in the second half of 2026, with inference devices using it in early 2027.
When will CXL pooling become mainstream?
CXL 2.0 pooling is already deployed in select hyperscale environments, and CXL 3.x fabrics are expected to spread after 2026. Most analysts see meaningful server attach rates building through 2028, though forecasts vary widely, so treat any specific adoption date as an estimate rather than a certainty.
Conclusion
CXL memory pooling is one of the most important architectural shifts in the data center precisely because it is so unglamorous: it does not make any single GPU faster, it just stops the industry from wasting the memory it already owns. CXL + DRAM is the mature, money-saving core of the thesis, freeing stranded capacity and pooling it across racks. CXL + Flash, from far-memory SSD tiers to Sandisk's High Bandwidth Flash, is the higher-risk frontier that could redraw the memory hierarchy if it standardizes on schedule.
For investors, the three things to remember are simple. First, the driver is the AI memory wall, and it is not going away. Second, the listed pure-plays, Astera Labs (ALAB) on connectivity and Sandisk (SNDK) on flash, offer concentrated exposure but already trade at demanding valuations. Third, the quieter beneficiaries may be the memory incumbents like Micron that supply the DRAM riding behind every CXL link. Get the architecture right, then let valuation discipline decide your entry.
Try it yourself: Analyze Astera Labs (ALAB) with Finance Halo's AI assistant to get instant technicals, fundamentals, and a read on whether the CXL trade still has room to run.
Disclaimer: This article is for educational purposes only and does not constitute investment advice. Always do your own research before making investment decisions.